
مقدمه ارزیابی سامانههای بایومتریک
زیست سنجی (بایومتریک) ایدهآل سیستمی است که با دریافت هر داده در مورد آن تصمیم درستی را اتخاذ کند.
یک سیستم زیست سنجی را میتوان به عنوان یک سیستم تشخیص/بازشناسی الگو دید. ناگزیر امکان دارد تصمیمات نادرستی بگیرد.
در ادامه انواع مختلف خطاها یی که یک سیستم بیومتریک ممکن است به آن برخورد کند را بررسی خواهیم کرد. برای دست پیدا کردن به یک دید جامعتر نسبت به رفتار خطاها در سیستمهای زیست سنجی مطالعهی 19795ISO/IEC پیشنهاد میشود.
سه دلیل عمده در سیستمهای بیومتریک که میتواند باعث ایجاد خطا شود:
- محدودیت اطلاعات: اطلاعات بدست آمده از برخی از ویژگیهای زیستی ممکن است شامل پارامترهای کمی باشد. به عنوان مثال اسکن ضربان قلب پارامترهای زیادی در اختیارمان قرار نمیدهد. به همین دلیل این اسکن در بهترین حالت نیز در مقابل اثر انگشت اطلاعات زیادی برای شناسایی فرد در اختیار ما نمیگذارد. همچنین محدودیت اطلاعات میتواند به علت استفادهی ناصحیح از حسگر نیز اتفاق بیافتد. حتی یک مقایسه کنندهی ایدهآل نیز زمانی که اطلاعات دریافت شده با اطلاعات ثبت شده به هنگام ثبتنام همپوشانی نداشته باشد، نخواهد توانست دو الگو را تطابق دهد.
- محدودیت سازندهی الگو: یک سازندهی الگوی ایدهآل به گونهای است که تمامی دادههای دریافت شده از سمت حسگر را به شکلی در الگو ذخیره کند. اما در عمل سازندههای الگو نمیتوانند تمام دادههای دریافت شده از حسگر را در الگو جای دهند و در طول این عمل ناگزیر بخشی از ویژگیها حذف میشوند یا اطلاعاتی به اشتباه در الگو ذخیره میشوند. همین امر میتواند موجب به وجود آمدن خطا در سیستم شود.
- محدودیت تغییرناپذیری: در نهایت قرار است الگوهای مربوط به یک فرد با در هنگام مقایسه مشابه یکدیگر و الگوهای متعلق به افراد مختلف متفاوت تشخیص داده شوند. یک مقایسه کنندهی ایدهآل لازم است به درستی ارتباط بین دو الگویی که به یک نمونه تعلق دارند را (با وجود تفاوت شرایط اسکن) تشخیص دهد. این بار نیز در عمل یک مقایسهکننده نمیتواند ارتباط بین دو الگو را به طور کامل مدل کند (به عنوان مثال به علت کافی نبودن دادههای آموزشی و یا به وجود آمدن دادههای پیشبنیی نشده در هنگام تست) و در نتیجه الگوهای مختلف از یک نمونه ممکن است به درستی تطبیق داده نشوند.
ماژول ساخت الگو
این ماژول یک یا چند مجموعه از ویژگیهای استخراج شده را دریافت میکند و یک الگو برای ویژگی مورد نظر برای فرد تولید میکند.
در حین تولید الگو ممکن است به علت کم بودن تعداد ویژگیهای دریافت شده، امکان ساخت الگو وجود نداشته باشد.
در این صورت خطا در ثبتنام (FTE) خواهیم داشت. معمولا یک ارتباط معکوس بین FTE و دقت سیستم برقرار است.
ماژول دریافت از حسگر، استخراج ویژگی
در یک سیستم خودکار زیستسنجی ممکن است در هنگام جمعآوری اطلاعات، به دو نوع خطا برخورد کند:
خطای عدم تشخیص (FTD) و خطای عدم دریافت اطلاعات (FTC).
در ادامه اگر دادهی دریافت شده از حسگر دارای کیفیت پایینی باشد، امکان پردازش آن و استخراج ویژگیهای کافی وجود نداشته باشد. در بخش استخراج ویژگی به خطای پردازش (FTP: Failure To Process) بر میخوریم.

ماژول تطبیق بایومتریک
این ماژول با تطابق دو الگو مقداری بین صفر تا یک به میزان شباهت آنها اختصاص میدهد. سپس ماژول تصمیمگیری با اعمال حداقل امتیاز لازم برای تطابق، در مورد مطابق بودن الگوها تصمیمگیری میکند. لازم به ذکر است که این ماژول دقیقا تطابق دو الگو را مورد بررسی قرار میدهد.
خطاهای ممکن در این بخش عبارتند از:
تطابق اشتباه (FMR) برای حالتی که دو الگو که متعلق به دو فرد متفاوت هستند را مطابق تشخیص دهد و عدم تطابق اشتباه (FNMR) برای حالتی که دو الگو که متعلق به یک فرد هستند را تطابق ندهد. خطاهای یاد شده برای این ماژول را با خطاهای پذیرش اشتباه و عدم پذیرش اشتباه نباید یکی فرض کرد پذیرش اشتباه و عدم پذیرش اشتباه به کاربردهایی مانند «تایید هویت» و «تعیین هویت» مرتبط هستند. اما با توجه به به کارگیری ماژول تطبیق در این دو کاربرد، خطاهای تطابق و عدم تطابق بر روی خطاهای پذیرش و عدم پذیرش تاثیرگذار هستند.
به عنوان مثال، در کاربرد «تایید هویت» که ادعای کاربر مبنی بر داشتن هویتی مشخص مورد بررسی قرار میگیرد. با رخ دادن خطای تطابق اشتباه بالا رفتن میزان خطای پذیرش اشتباه و با رخ دادن خطای عدم تطابق اشتباه بالا رفتن میزان خطای عدم پذیرش اشتباه را خواهیم داشت. علاوه بر این یک سیستم زیستسنجی ممکن است برای پذیرش یا رد در کاربردهای یاد شده علاوه بر امتیاز تطابق از معیارهای دیگری نیز استفاده کند. به همین دلیل میتوان گفت میزان خطای تطابق یا عدم تطابق در یک سیستم مستقل از کاربرد بوده. به همین علت معیار مناسبتری برای مقایسه به شمار میروند. در کاربرد «تعیین هویت» ماژول تطبیق به صورت یک به چند عمل میکند که در سادهترین فرم میتوان آن را به صورت چند مقایسهی یک به یک در نظر گرفت.در صورتی که دستگاه تنها افراد ثبتنام شده در سیستم قابل استفاده باشد، اصطلاحاً آن را «تعیین هویت مجموعهی بسته» مینامند.
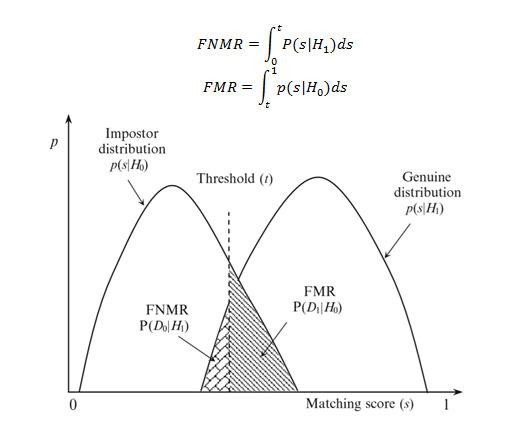
در بخش گذشته خطاهای ممکن برای ماژول تطبیق را تعریف کردیم. این خطاها برای مقایسههای یک به یک تعریف میشوند و از آنجایی که تایید هویت در سیستمهای زیستسنجی نیز یک تطابق یک به یک است. خطای تطابق و عدم پذیرش را همان خطای تطابق در نظر میگیریم. در صورتی که الگوی ذخیره شده در پایگاه داده از یک فرد را T بنامیم و الگوی دریافت شده از حسگر را I بنامیم، یکی از دو فرضیهی زیر را خواهیم داشت:
- H0 الگوهای T و I مربوط به دو هویت مجزا باشند.
- H1 الگوهای T و I مربوط به یک هویت واحد باشند.
و در نهایت تصمیم گیری سیستم تایید هویت، یکی از دو نتیجهی زیر را تولید خواهد کرد.
- D0 عدم تطابق
- D1 تطابق
سیستم تایید هویت با استفاده از s(T, I) (همان مقدار امتیازی که به تشابه بین I و T داده شده است) یکی از دو نتیجهی فوق را باز میگرداند. اگر امتیاز داده شده از مقدار آستانه تعریف شده برای سیستم کمتر باشد، D0 و در غیر این صورت D1 را به عنوان خروجی باز گردانده میشود. با توجه به معیارهای تعریف شده در بالا برای سیستم تایید هویت دو نوع خطا میتوان انتظار داشت:
- نوع یک: تطابق اشتباه (تصمیمگیری D1 در حالی که H0 برقرار باشد)
- نوع دو: عدم تطابق اشتباه (تصمیمگیری D0 در حالی که H1 برقرار باشد)
برای اندازهگیری دقت تایید هویت یک سیستم زیستسنجی، به مقادیر امتیازهای تعداد زیادی مقایسه نیاز داریم به شرطی که الف) الگوی دریافتی و الگوی ثبت شده در پایگاه داده متعلق به یک هویت باشد ب) الگوی دریافتی و الگوی ثبت شده در پایگاه داده متعلق به یک هویت نباشد. در صنعت، به توزیع امتیازها با شرط الف، توزیع اصل (genuine distribution) و به توزیع امتیازها با شرط ب، توزیع تقلب (impostor distribution) گفته میشود. مقادیر FMR و FNMR را میتوان از روی این توزیعها به کمک فرمول زیر محاسبه کرد (لازم به ذکر است فرض میشود که نمونههایی با امتیازی بیشتر از t توسط الگوریتم پذیرفته میشوند و مقادیر کمتر از آن رد میشوند).
در مقایسهی ویژگیهای زیستسنجی به صورت «یک به چند» امکان به وجود آمدن «خطای عدم تشخیص هویت» (FNIR) و «خطای تشخیص هویت نادرست» (FPIR) وجود دارد.
مشابه FMR و FNMR قابل محاسبه است.
اما این خطاها با در نظر گرفتن شرایط مسئله (به عنوان مثال این که از بین کل پایگاه داده تشخیص صورت میگیرد.
یا تنها یک بخش از پایگاه داده) از روی مقادیر FMR و FNMR نیز قابل تخمین میباشند.
به همین علت در سیستمهای زیستسنجی، معمولا به گزارش خطاهای تایید هویت بسنده میشود.
مقایسهی سیستمها نیز بر اساس همان FMR و FNMR صورت میگیرد.


