
بازشناسی چهره و مکانیابی چهره
همانطور که در مبانی سامانههای تشخیص چهره بیان شد، عملیات مقایسه در فرآیند تشخیص چهره با استفاده از یک عکس خاکستری مانند هر سیستم زیستسنجی دیگر، مراحلی مشابه شکل زیر طی میشود. به این صورت که ابتدا سیستم یک عکس حاوی چهره دریافت میکند، مکان چهرهی انسان را در عکس تشخیص میدهد، قسمت چهره از عکس بریده شده، نرمال میشود و ويژگیهای آن استخراج میشود و بدین ترتیب الگوی تصویر صورت تشکیل میشود. در هنگام تشخیص هویت، همانطور که در این شکل ملاحظه میشود، این الگوی دریافت شده با الگوهای موجود در پایگاه داده مقایسه میشود.
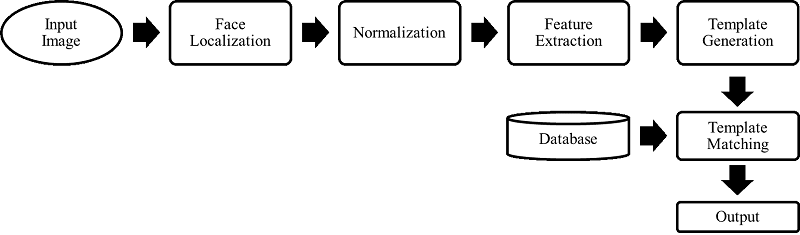
عملیات مقایسه در یک سیستم تشخیص چهره
بدین ترتیب دو بخش اصلی این الگوریتم ۱) مکانیابی چهره و نرمالسازی و ۲) تشخیص هویت چهره خواهد بود. الگوریتمهایی که هر دو بخش را در بر میگیرند، الگوریتمهای تشخیص چهرهی تمام اتوماتیک و الگوریتمهایی که تنها بخش دوم را شامل میشوند الگوریتمهای نیمه اتوماتیک نامیده میشوند. قبلا در مکانیابی چهره در سامانههای تشخیص چهره در در بخش اول صحبت شده بود، در ادامه در مورد قسمت دوم (تشخیص هویت) صحبت میشود.
روشهای تشخیص هویت به کمک چهره
در یک سیستم تشخیص هویت به کمک چهره، پس از مکانیابی چهره در تصویر و پیشپردازش آن، وارد مرحلهی بعدی یعنی استخراج ویژگی از چهره و تشکیل الگوی چهره میشود. الگوریتمهای تشخیص چهره را میتوان در یک دستهبندی کلی به دو بخش تقسیمبندی کرد:
۱) روشهای کلی
۲) روشهای بر پایهی اجزای صورت.
در روشهای کلی، ویژگیهای کل صورت در یک بردار ذخیره میشود. این بردار را میتوان به عنوان ورودی به طبقهبند داد. اما در روشهای بر پایهی اجزا صورت، هر یک از اجزا به صورت جداگانه مکانیابی شده و ترکیب آن اجزا با یکدیگر در تشخیص هویت چهره به کار میروند.
به عنوان یک روش بارز که «بر پایهی اجزای صورت» پیادهسازی شده، میتوان به کار ارائه شده در پژوهش زیر اشاره کرد،
- Heisele, P. Ho, and T. Poggio, “Face recognition with support vector machines: Global versus component-based approach,” in Proceedings of the IEEE International Conference on Computer Vision, 2001, vol. 2, pp. 688–694.
مزیت این روش نسبت به روشهای کلی این است که برای تغییر زاویههای جزئی در صورت، تغییرای که در هر یک از اجزا به تنهایی ایجاد میشود، به نسبت تغییرات کلی صورت بسیار کمتر است و بدین ترتیب سیستم نسبت به چرخش و تغییر حالت مقامت بیشتر نشان خواهد داد. شکل زیر نمایش دهندهی اجزا مورد استفاده در این الگوریتم تشخیص چهره است. این روش این اجزا پس از تغییر اندازه با یکدیگر ترکیب شده و پس از آن با اعمال الگوریتم SVM به صورت «یکی در مقابل سایرین» مدلی برای تشخیص چهره از بین یک پایگاه داده آموزش داده شده است.
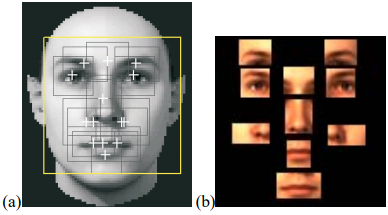
(a) تمامی 14 جزء صورت که مکانیابی میشوند
(b) اجزا مورد استفاده در الگوریتم شناسایی هویت این روش (10 جزء)
«روشهای کلی» برای تشخیص چهره از زاویهی روبهرو به خوبی عمل میکنند اما مقاومت این روشها در مقابل تغییرات زاویه مناسب نیست، به این علت که ویژگیهای ظاهری با تغییرات زاویه بسیار تغییر پذیر هستند. با همتراز (Alignment) کردن تصاویر چهره با یک تصویر مرجع، پیش از اعمال طبقهبند میتوان تا حدی این مشکل را بهبود داد. در طول همتراز کردن تصویر، نقاط خاصی از تصویر (مانند نقطهی وسط دو چشم و نقاط دو طرف دهان) در نظر گرفته میشود و به مختصات مشخصی منتقل میشوند. از جمله روشهای کلاسیک و مهم این زمینه الگوریتم eigenface میباشد. این روش که در ابتدای دههی ۱۹۹۱ میلادی ارائه شد، یکی از زمینههای رشد زمینهی تشخیص چهره به شمار میرود. الگوریتمهای بر پایهی تطابق گرافها (Graph matching)، مدل مخفی مارکف (Hidden Markov model)، تطابق ویژگی هندسی (Geometrical feature matching)، تطابق نمونهها (Template matching)، نقشهی خطوط لبه (LEM: Line edge map) و همچنین SVM نیز از دیگر روشهایی هستند که در مسئلهی تشخیص هویت به کمک چهره به کار رفتهاند.
یک دستهبندی دقیقتر از الگوریتمهای تشخیص چهره و سیر پیشرفت آنها را می توان در شکل زیر مشاهده کرد.
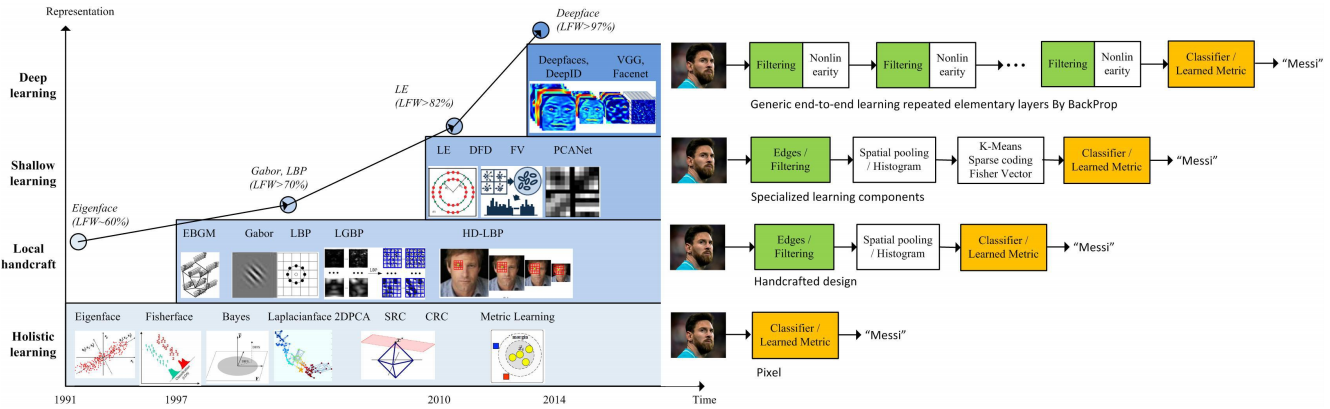
سیر تحول الگوریتمهای تشخیص چهره و دقت هریک در محک (Benchmark) LFW از دههی ۱۹۹۰ تا به امروز
از یک منظر، الگوریتمهای تشخیص چهره را میتوان در این چهار دسته قرار داد:
- یادگیری کلی: در این روشها که بیشتر در دههی ۱۹۹۰ و اوایل دههی ۲۰۰۰ میلادی مورد توجه قرار گرفتند، تلاش بر این بود که به کمک یک پراکندگی فرضی، یک بازنمایی با تعداد ابعاد محدود برای هر چهره ارائه شود. اولین و بارزترین نمونهی روش، eigenface است. در سالهای ۱۹۸۷ و ۱۹۹۰ میلادی در مقالات مختلفی با استفاده از تحلیل مولفههای اصلی (PCA: Principal component analysis)، یک بازنمایی بهینه از تصویر چهره به کمک برداری از اعداد ارائه شد و نشان داده شد تصویر هر چهره را میتوان با همراه داشتن یک مجموعه تصویر استاندارد و یک بردار از ضرایب نمایش داد. پس از آن در سال ۱۹۹۱ میلادی، با الهام از پژوهشهای قبلی روشی با عنوان eigenface برای طبقهبندی تصاویر چهره ارائه شد. این روشها تحت شرایط محیطی مختلف معمولا با مشکل مواجه میشوند.
- ویژگیهای محلی: در دههی ۲۰۰۰ میلادی، روشهایی بر پایهی ویژگیهای محلی (مانند نتایج فیلترهای گابور) ارائه شد. این روشها تا حدودی نسبت به شرایط محیطی مختلف مقاومت نشان میدادند اما فشردگی کافی را نداشتند و همچنین قابلیت ایجاد متمایز در آنها کافی نبود. پژوهش زیر که بر پایهی فیلترهای گابور ارائه شد، به عنوان یک روش بارز در این بخش شناخته میشود.
Liu and H. Wechsler, “Gabor feature based classification using the enhanced Fisher linear discriminant model for face recognition,” IEEE Trans. Image Process., vol. 11, no. 4, pp. 467–476, 2002.
- یادگیری کمعمق: در اوایل دههی ۲۰۱۰ میلادی روشهایی ارائه شدند که در آنها توصیفگرهای محلی بر پایهی یادگیری معرفی شدند. در واقع در این روشها با توجه به پایگاه داده، فیلترهایی آموزش داده میشوند که بیشترین ایجاد تمایز را ایجاد میکنند. اما هنوز این روشها مقاومت کافی در برابر تبدیلهای غیر خطی و پیچیدهی چهره را نداشتند. پژوهش زیر نمونه روش ارائه شده در این زمینه است.
Cao, Q. Yin, X. Tang, and J. Sun, “Face recognition with learning-based descriptor,” in Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2010, vol. 91, no. 6, pp. 2707–2714.
- یادگیری عمیق: در سال ۲۰۱۴ میلادی با ارائهی الگوریتم DeepFace توسط تیم تحقیقاتی شرکت Facebook سری دیگری از روشهای تشخیص چهره بر پایهی یادگیری عمیق کلید خورد. در این روشها بر خلاف روشهای یادگیری کمعمق، تعداد لایههای زیادی به صورت متوالی به منظور استخراج ویژگی و تبدیل آنها در نظر گرفته شده و بدین ترتیب در سطوح ویژگیهای مختلفی با سطوح پیچیدگی مختلف شناسایی میشوند و این ویژگیها نسبت به حالت چهره و شرایط محیطی نیز مقاوم هستند. لازم به ذکر است DeepFace برای اولین بار دقت الگوریتمهای تشخیص چهره را به دقت تشخیص چهره توسط انسان (حدود ۹۷ درصد) رسانید. پس از ارائهی DeepFace الگوریتمهای دیگری نیز بر پایهی یادگیری عمیق تشخیص چهره کردند از جملهی این روشها میتوان به FaceID، VGGFace، VGGFace2 و FaceNet اشاره کرد. الگوریتم FaceNet در سال ۲۰۱۵ توسط تیم تحقیقاتی شرکت Google ارائه شد. این روش از یادگیری عمیق برای تشخیص چهره استفاده کرده و بر خلاف روش DeepFace که یک مدل سه بعدی از چهره ساخته و برای همترازی و شناسایی از آن بهره میگیرد، FaceNet روش سادهتری برای تشخیص چهره ارائه کرده و با افزایش تعداد پارامترها و لایههای شبکه، بار پردازشی بیشتری را بر روی آن قرار داده است. مقاومت الگوریتم در مقابل تغییرات نور و زاویه در شکل زیر دیده میشود. لازم به ذکر است که در این پژوهش در عکسهای ورودی سیستم، از محدودهی چهره گرفته شدهاند (مانند تصاویر شکل زیر) و فرض شده است که عمل مکانیابی پیش از آن انجام شده است.

اعداد بین هریک از دو تصویر، بیانگر فاصلهی بین دو تصویر است. فاصلهی صفر به معنای تصاویر همسان و فاصلهی ۴ به تصاویر دو هویت مجزا تعلق میگیرد.
ملاحظه میشود با در نظر گرفتن آستانهی ۱/۱ میتوان دستهبندی افراد در تصاویر را به درستی انجام داد.


